ElasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
- Near Realtime
- 从写入数据到数据可以被搜索到有一个小延迟,大概是 1s
- 基于 es 执行搜索和分析可以达到秒级
优势
- 横向可扩展
- 分片机制提供更好的分布性
- 高可用
安装
使用 docker
docker run elasticsearch:7.3.1
docker network create somenetwork;
docker run -d --name elasticsearch --net somenetwork -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.3.1
9300端口: ES节点之间通讯使用 9200端口: ES节点 和 外部 通讯使用
图形化管理界面
概念
- 集群(cluster)
- 多个节点组成
- 节点(node)
- 服务器实例
- 索引(index)
- Databases 数据库
- 类型(type)
- Table 数据表
- 文档(Document)
- Row 行
- 字段(Field)
- Columns 列
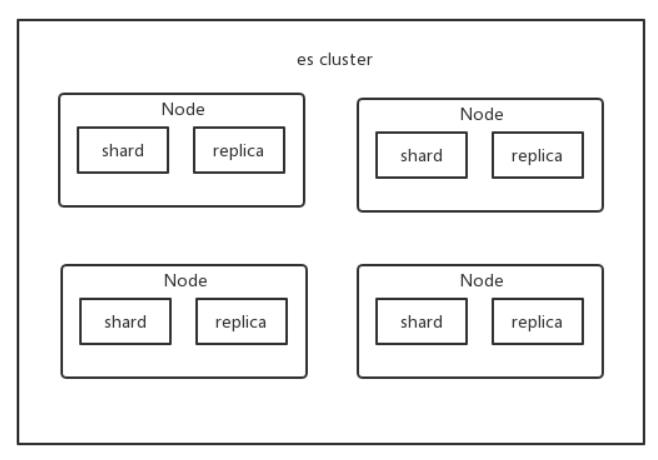
- shard
- es 可以将一个索引中的数据切分为多个 shard,分布在多台服务器上存储
- replica
- 任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个replica 副本。replica 可以在 shard 故障时提供备用服务,所以同一片shard跟replica不能存放在同一节点
- 映射 mapping
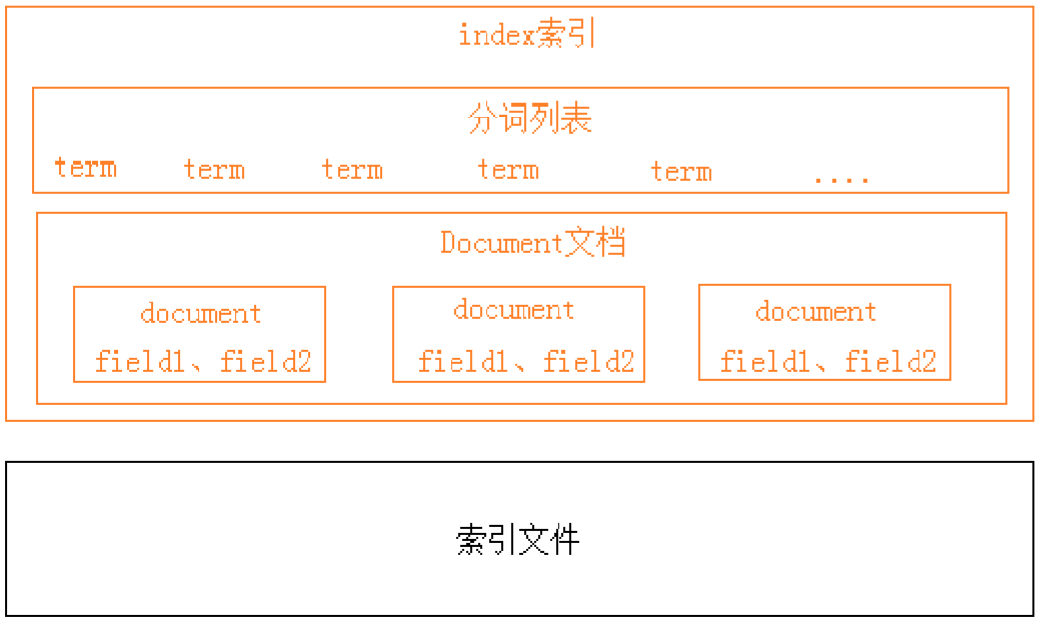
索引结构
操作
创建索引
PUT /blog
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
- 获取索引库信息
GET /blog
- 删除索引库
DELETE /blog
添加映射
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
数据类型
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。 keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索) 数值型:long、integer、short、byte、double、float 日期型:date 布尔型:boolean 二进制型:binary
- 查看映射关系
GET /索引库名/_mapping
- 更新索引
POST http://my-pc:9200/blog/{indexName}
添加文档
POST /索引库名/类型名
{
"key":"value"
}
- 自定义id
POST /索引库名/类型/id值
{...}
删除文档
DELETE http://my-pc:9200/blog/hello/1
修改文档
UPDATE http://my-pc:9200/blog/hello/1
查询
基本查询
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
- 根据ID查询
GET http://my-pc:9200/blog/hello/1
- 根据字段查询
Term Query为精确查询,在搜索时会整体匹配关键字,不再将关键字分词。
GET /shop/_search
{
"_source": ["title","price"],
"query": {
"term": {
"price": 2699
}
}
}
- queryString查询
{
"query":{
"query_string":{
"default_field":"content",
"query":"内容"
}
}
}
过滤
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
GET /shop/_search
{
"_source": {
"includes":["title","price"]
},
"query": {
"term": {
"price": 2699
}
}
}
排序
GET /shop/_search
{
...
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
模糊查询
GET /heima/_search
{
"query": {
"fuzzy": {
"title": {
"value":"appla",
"fuzziness":1
}
}
}
}
分词
内置的分词器
- Standard Analyzer
- Simple Analyzer
- Whitespace Analyzer
- Stop Analyzer
- Keyword Analyzer
- Pattern Analyzer
- Language Analyzers
- Fingerprint Analyzer
测试分词
GET /_analyze
{
"analyzer": "standard",
"text": "中文测试分词"
}
中文分词器
docker run --name elasticsearch --net somenetwork -v /root/plugin:/usr/share/elasticsearch/plugins -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.3.1
GET http://my-pc:9200/_analyze
{
"analyzer": "ik_max_word",
"text": "中文测试分词"
}
ik 的两种模式:
- max:会将文本做最细粒度的拆分 会穷尽所有的可能
- smart:最最粗粒度的划分
聚合
桶
ES集群
采用ES集群,将单个索引的分片到多个不同分布式物理机器上存储,从而可以实现高可用、容错性
架构
es 集群多个节点,会自动选举一个节点为 master 节点 master 节点宕机了,那么会重新选举一个节点为 master 节点
非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard
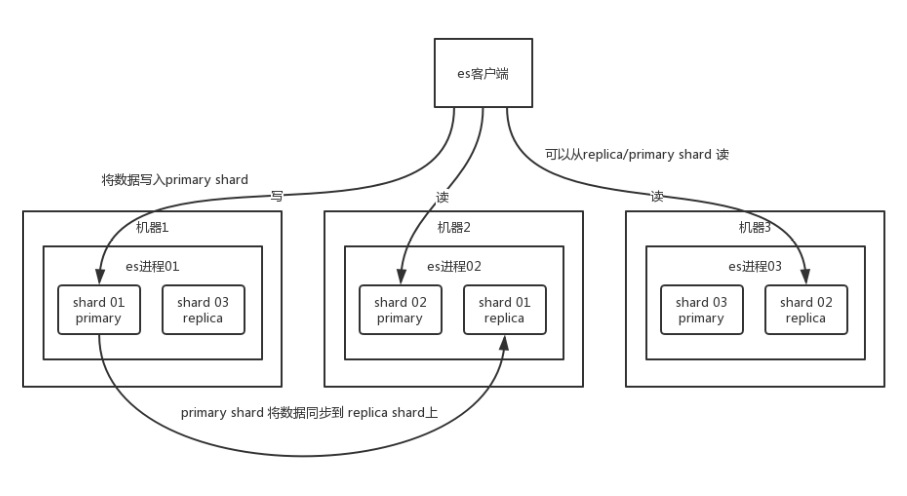
可以使用三个节点,将索引分成三份,每个节点存放一份primary shard,两份replica,这样就算只剩下一台节点,也能保证服务可用
搭建
- 配置
# 集群名称,必须保持一致
cluster.name: elasticsearch
# 节点的名称
node.name: node-1
# 监听网段
network.host: 0.0.0.0
# 本节点rest服务端口
http.port: 9201
# 本节点数据传输端口
transport.tcp.port: 9301
# 集群节点信息
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
另外两个节点配置省略...
JAVA客户端
- 依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.3.1</version>
</dependency>
- 连接
Settings settings = Settings.builder()
.put("cluster.name","docker-cluster")
.build();
TransportClient client = new PreBuiltTransportClient(settings);
client.addTransportAddress(
new TransportAddress(InetAddress.getByName("my-pc"),9300));
- 创建索引
client.admin().indices().prepareCreate("index").get();
- 设置映射
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "long")
.field("store", true)
.endObject()
.startObject("title")
.field("type", "text")
.field("store", true)
.field("analyzer", "ik_smart")
.endObject()
.startObject("content")
.field("type", "text")
.field("store", true)
.field("analyzer", "ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
client.admin().indices().preparePutMapping("index")
.setType("article")
.setSource(builder)
.get();
- 添加文档
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("id",1L)
.field("title","央视快评:勇做敢于斗争善于斗争的战士")
.field("content","9月3日,习近平总书记在中央党校(国家行政学院)中青年干部培训班开班式上发表重要讲话强调,广大干部特别是年轻干部要经受严格的思想淬炼、政治历练、实践锻炼,发扬斗争精神,增强斗争本领,为实现“两个一百年”奋斗目标、实现中华民族伟大复兴的中国梦而顽强奋斗。")
.endObject();
client.prepareIndex("index","article","1")
.setSource(builder)
.get();
- POJO添加文档
Article article = new Article();
article.setId(3L);
article.setTitle("3央视快评:勇做敢于斗争善于斗争的战士");
article.setContent("9月3日3333,(国家行政学院)中青年干部培训班开班式上发表重要讲话强调,广大干部特别是年");
String json = new ObjectMapper().writeValueAsString(article);
client.prepareIndex("index","article","3")
.setSource(json, XContentType.JSON)
.get();
查询
- 根据ID
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("1","2");
SearchResponse response = client.prepareSearch("index")
.setTypes("article")
.setQuery(queryBuilder)
.get();
SearchHits hits = response.getHits();
System.out.println("总记录:"+hits);
SearchHit[] ret = hits.getHits();
for (SearchHit documentFields : ret) {
Map<String, Object> map = documentFields.getSourceAsMap();
System.out.println("id:"+map.get("id"));
System.out.println("title:"+map.get("title"));
System.out.println("content:"+map.get("content"));
System.out.println("-------------------");
}
- 根据term
QueryBuilder queryBuilder = QueryBuilders.termQuery("title","斗争");
- 根据queryString
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("青年强调")
.defaultField("content");
- 分页查询
SearchResponse response = client.prepareSearch("index")
.setTypes("article")
.setQuery(queryBuilder)
.setFrom(10)
.setSize(5)
.get();
- 高亮显示结果
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field(highlight);
highlightBuilder.preTags("<em>");
highlightBuilder.postTags("</em>");
SearchResponse response = client.prepareSearch("index")
.setTypes("article")
.setQuery(queryBuilder)
.highlighter(highlightBuilder)
.get();
SearchHits hits = response.getHits();
System.out.println("总记录:"+hits.getTotalHits());
SearchHit[] ret = hits.getHits();
for (SearchHit documentFields : ret) {
Map<String, Object> map = documentFields.getSourceAsMap();
System.out.println("id:"+map.get("id"));
System.out.println("content:"+map.get("content"));
Map<String, HighlightField> highlightFields = documentFields.getHighlightFields();
System.out.println(highlightFields.get(highlight).getFragments()[0]);
System.out.println("-------------------");
}
es操作过程
写过程
客户端选择一个协调节点(coordinating node)发送请求,协调节点将请求转发给对应的node 对应的node在primary shard上处理请求,并同步到replica shard上
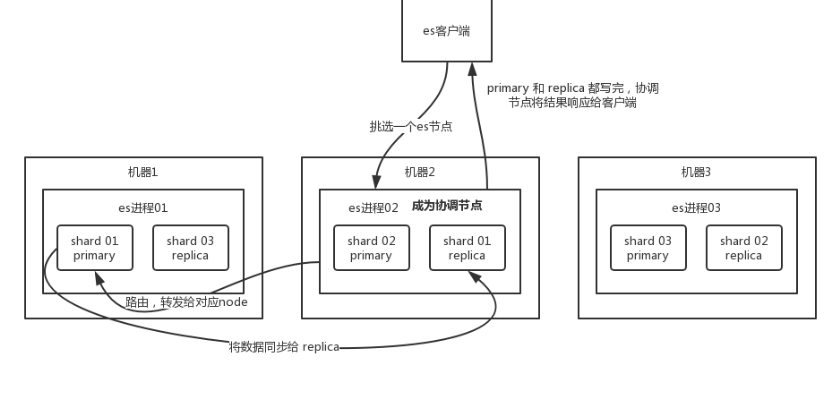
写过程原理
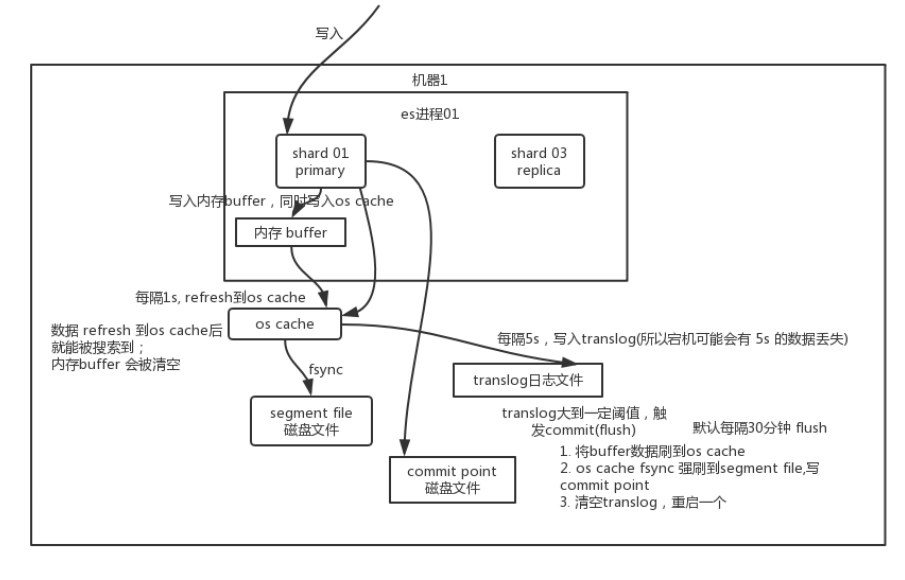
数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到
每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中
读过程
客户端选择一个协调节点(coordinating node)发送根据ID查询请求,协调节点会根据id进行哈希,得到doc所在的分片,将请求转发到对应的node 这个node然后会在primary shard与replica中使用随机轮询,进行负载均衡,返回document给协调节点 协调节点再把document返回给客户端
搜索过程
客户端发送搜索请求给协调节点,协调节点将这个请求发送给所有的shard 每个shard将自己的搜索结构返回给协调节点 由协调节点进行数据的合并、排序、分页等操作,产出最终结果 接着协调节点根据id再去查询对应的document的数据,返回给客户端
删除/更新过程
删除操作,会生成一个对应document id的.del文件,标识这个document被删除 如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据
每refresh一次,会生成一个segment file,系统会定期合并这些文件,合并这些文件的时候,会物理删除标记.del的document
性能优化
杀手锏:filesystem cache
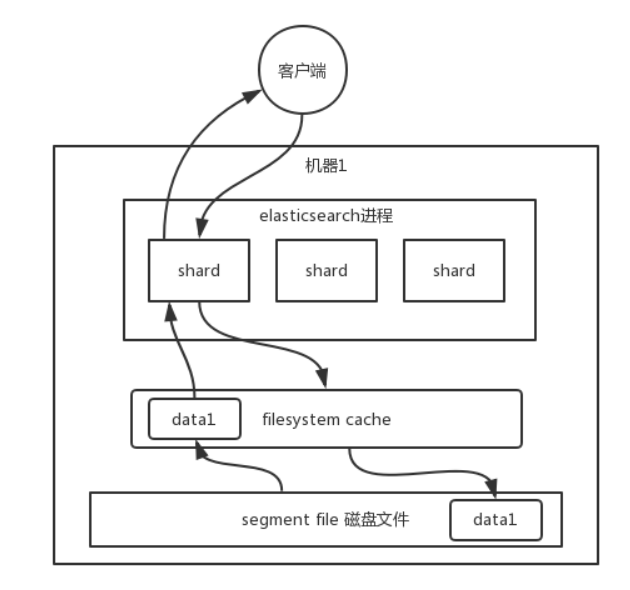
在es中,doc的字段尽量只存储要被搜索的字段,这样可以节省内存,存放更多数据,做缓存效果更好
数据预热
对于一些热点数据,也要通过一些方式让它在缓存中
冷热分离
保证热点数据都在缓存里,提高系统性能
doc模型设计
对于一些复杂的关联,最好在应用层面就做好,对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的
分页性能优化
由于分页操作是由协调节点来完成的,所以翻页越深,性能越差 解决:
- 不允许深度翻页
- 将翻页设计成不允许跳页,只能一页一页翻
kibana
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
- docker
docker pull kibana:5.6.8 # 拉取镜像
docker run -d --name kibana --net somenetwork -p 5601:5601 kibana:5.6.8 # 启动
SpringDataElasticSearch
配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
https://www.springframework.org/schema/data/jpa/spring-jpa.xsd http://www.springframework.org/schema/data/elasticsearch http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch.xsd">
<elasticsearch:transport-client id="esClient" cluster-name="docker-elasticsearch"
cluster-nodes="my-pc:9300"/>
<elasticsearch:repositories base-package="wang.ismy.es"/>
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="esClient"/>
</bean>
</beans>
@Document(indexName = "index1",type = "article")
@Data
public class Article {
@Id
@Field(type = FieldType.Long,store = true)
private long id;
@Field(type = FieldType.Text,store = true)
private String title;
@Field(type = FieldType.Text,store = true)
private String content;
}
@Repository
public interface ArticleDao extends ElasticsearchRepository<Article,Long> { }
创建索引
ElasticsearchTemplate template = context.getBean(ElasticsearchTemplate.class);
template.createIndex(Article.class);
添加文档
Article article = new Article();
article.setId(1L);
article.setTitle("【中国稳健前行】“中国之治”的政治保证");
article.setContent("新中国成立70年来,在中国共产党的坚强领导下,...");
articleDao.save(article);
删除文档
articleDao.deleteById(1L);
articleDao.deleteAll(); // 全部删除
修改文档
同添加文档
查询
- 查询全部
articleDao.findAll().forEach(System.out::println);
- 根据ID
System.out.println(articleDao.findById(2L).get());
自定义查询
@Repository
public interface ArticleDao extends ElasticsearchRepository<Article,Long> {
List<Article> findAllByTitle(String title);
}
- 分页查询
List<Article> findAllByTitle(String title, Pageable pageable);
articleDao.findAllByTitle("中", PageRequest.of(0,5)).forEach(System.out::println);
- 原生查询
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("中国").defaultField("title"))
.withPageable(PageRequest.of(0,5))
.build();
template.queryForList(query,Article.class).forEach(System.out::println);